AI for coding on a large codebase with a big team in June 2025
Table of Contents
AI for coding on a large codebase with a big team, so far#
Everyone’s dealing with the introduction of AI into the wild at this point. Either explicitly by going all-in and pushing people to use it as much as possible, or it being outright banned and there’s a significant portion of people using it in the shadows in unideal ways.
Where we are today#
We’ve landed somewhere in the middle at ShipHero (in June 2025, I’m sure this will be out of date in like 2 weeks!). We’ve adopted an official AI code assisting tool (SourceGraph Cody) and signed up for the enterprise plan so we’re fully in compliance, and made it available to everyone in the company. People use it for both auto-completion and agentic coding (chatting with it and having it output code until it looks like what you want).
How we got there#
It took a bit of time (and stress) to decide on what to use, how to use it and when to use it. The primary concern was how making it easier to auto-generate code on a large codebase (1.6M lines of code) with a big group of people making changes to it (100+ developers) would affect the quality of the software.
We had been using Github’s co-pilot for a while because it was one of the first one’s easily available and compliant (we had turned on only using trained data on open source code). It was ok, but seemed to be behind what we were seeing with other tools out there.
The concern was (and still is) that the bottleneck in software development on teams over a handful of developers quickly becomes reviewing code. Producing code faster means there’s more to review, and when the people producing it did it faster without having to have to type it out you put more pressure on the reviewer to make sure everything makes sense. Good code reviewers are much scarcer than developers.
What works well#
Agentic coding is great when you know what you want. Being able to tell it to look at a set of tests and produce one within the same framework saves you a lot of time you’d usually prefer not to spend on that.
Encoding rules that go beyond traditional linters is really exciting. It lets you empower the more experienced folks in the company to set guidelines in a way that it automatically nudges everyone else towards them instead of having to rely as much on training and blocking code at the review stage.
This is particularly important when you make decisions that are different from the existing patterns in the codebase, as the years go by you often find yourself wanting to implement better patterns but the current LLMs tend to work against you by reinforcing what they see the most.
So being able to inject shared context into a team is really powerful.
Here’s an example of that sort of rule:
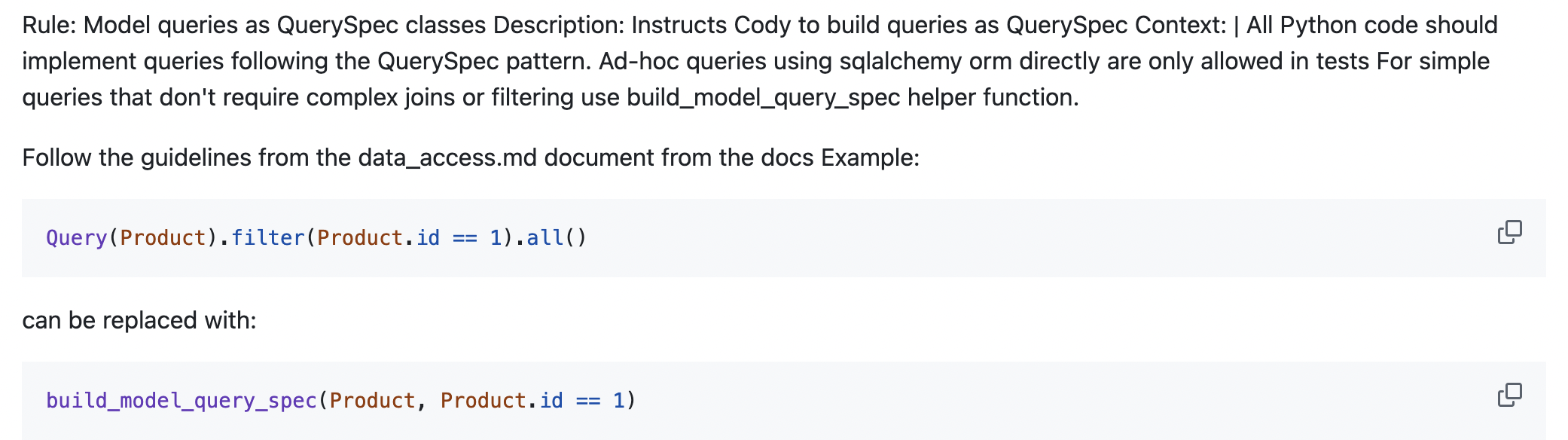
I do think you still want to encode guidance and rules into linters where possible because they’re deterministic, even if sometimes rough to deal with.
Another example is:

Dealing with stylistic changes is also easier. It’s the sort of mechanical changes that are annoying to do but will prevent a whole class of errors and make the code look great when applied consistently. You can often get them all applied with a simple prompt.
Spinning up proof-of-concept code quickly is also a huge leap forward. I won’t mention a lot more on that since it seems to be what gets talked about the most.
The more you know what you want, the more useful the current tools are.
What doesn’t work well#
It’s not great with existing large codebases. Gemini is leading the pack today in their Gemini 2.5’s context window at 1 million tokens, which translates to maybe 50k lines of code (750k words). We’re at 1.6M lines, so very far away from it just working out of the box.
This pushes more work onto the user today to try and feed it the right context for their task, which reinforces that it works well when you know what you want, but it’s tougher when you don’t (750k words).
Iterating on code is a bit of a roulette right now. You spin the wheel and aren’t sure what you’re going to get. When you’re refining code you usually want to change less and less of it as you get closer to the outcome that you want, but current tools tend to change many things that were working well and make it less ideal for refining code.
Managing engineers that are struggling is harder. When people struggle at work their output goes down fairly drastically, it’s usually one of the strongest signals that someone needs some support. Having agents that you can copy and paste your ticket into and have it produce something that resembles the right thing allows people to fly under the radar longer. The problem here again is that they do so now at the expense of the code reviewers, who have to spend more time trying to understand something that just doesn’t make sense.
Not all IDEs are great at applying the context in the rules we set. It sometimes doesn’t get loaded, or it does but gets pushed out of the context window after a while. I hope you get to mark some pieces of context as more important than others soon.
What’s next#
As we iterate on what our prompted rules look like, we can re-use them to do a first-pass code review to adjust a few of the basics before a human gets their hands on it.
The introduction of AI is pushing us to think about different ways to structure our codebase so it’s easier to stay within the context window. Some of that will also help developers by making things easier to find.
In a world where code is faster to produce (at the expense of quality, but that’s always been the case), there are some opportunities to build some things that don’t need to be as reliable quickly, on top of other things that need to be 100% reliable. The speed that’s available now to churn out code is making us re-think where we need to increase the quality and where we can trade-off quality for speed while still making it a good user experience.