Upgrading MySQL: The ShipHero Approach
Table of Contents
🔧 Upgrading MySQL Software: The ShipHero Approach#
Database upgrades aren’t optional—they’re mission-critical. Older MySQL versions eventually reach end-of-support, meaning no more security patches or bug fixes. Running unsupported versions exposes our systems, our customers, and our business to security vulnerabilities and operational risks.
In 2024, we migrated our Aurora MySQL fleet from 5.7 to 8.0. This approach—automated, observable, and fully reversible—is now the ShipHero standard for every upgrade we perform, applied consistently across all our services and databases. It is used for every upgrade, from minor patches to major versions.
For us, every upgrade is about:
🛡️ Security: Applying critical patches and safeguarding customer data.
⚡ Stability: Ensuring our platform handles thousands of real-time orders across multiple services with minimal disruption.
💰 Cost Efficiency & Performance: Avoiding high costs for extended support from cloud providers while unlocking new features and performance improvements in our databases.
🔄 Upgrade Strategies for MySQL#
When evaluating an upgrade, we looked at the most common strategies and assessed which one would meet our requirements for control and predictability:
🏗️ In-place upgrade: While simple, the risk of extended downtime and an impossible rollback scenario made this a non-starter for critical workloads.
☁️ AWS RDS Blue/Green: Although AWS manages much of the complexity, its “black box” nature was a dealbreaker. We couldn’t rely on a managed solution for a guaranteed, instant rollback. Additionally, our Change Data Capture (CDC) pipelines—powered by Debezium and Kafka—could not tolerate the interruption of binlog streams introduced by AWS’s process.
🔧 Self-managed parallel cluster with replication: This gave us full operational control. We could test with live traffic, ensure our CDC pipelines ran without interruption, and most importantly, design a robust, immediate rollback plan. ✅
After evaluating all strategies, a self-managed parallel cluster with replication was the only approach that gave us full control, zero downtime for CDC pipelines, and a reliable rollback plan.
⚙️ Our Architectural Stack#
Our migration strategy is built on a robust, self-managed architecture designed for full control and observability.
All applications connect to a ProxySQL cluster. ProxySQL is a high-performance, open-source database proxy that acts as a traffic routing layer. It sits between our applications and the database servers, allowing us to manage and route all database queries. This cluster, fronted by a Network Load Balancer, directs all database queries to the appropriate Aurora MySQL clusters. This setup is a prerequisite for our migration process, ensuring all database traffic flows through a single, controllable endpoint. For more information, you can refer to the official ProxySQL documentation.
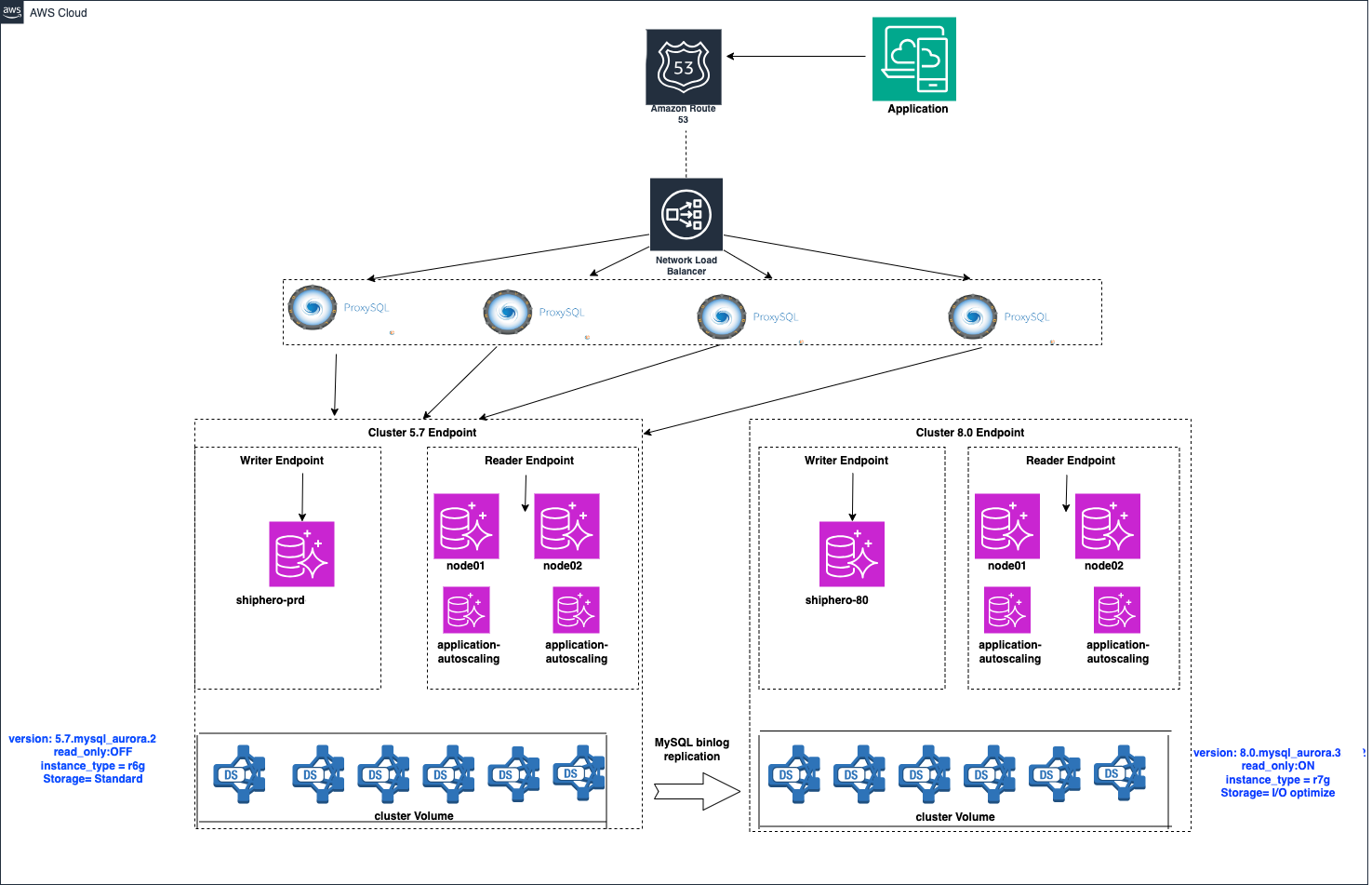
🛠️ The Migration Execution: A Closer Look#
Our five-step process was designed to be predictable and safe. Here’s a closer look at the technical decisions behind each stage:
1️⃣ Parallel Cluster Setup#
We provisioned a new Aurora MySQL 8.0 cluster from a snapshot of our 5.7 primary. Using Terraform, we applied all our standard policies, ensuring the new cluster was compliant with our internal standards from day one.
Crucially, we configured this new 8.0 cluster as an external replica of the 5.7 primary. This setup allowed us to:
🔄 Replicate all data changes in real time.
⏱️ Verify replication lag and ensure the new cluster was always in sync.
2️⃣ Query Mirroring with ProxySQL#
This step was the key to our success. We used ProxySQL, a high-performance MySQL router, to achieve query mirroring.
What is Query Mirroring?
ProxySQL’s mirroring feature allows you to send a copy of all queries destined for one hostgroup (e.g., your production cluster) to another hostgroup (e.g., your new cluster). The results from the mirrored queries are ignored, so they don’t affect the application’s response.
This is a powerful technique for validating the performance and behavior of a new database version under live production workload without risk.
For detailed configuration, see the official ProxySQL documentation.
Example Configuration#
-- Step 1: Add the new server to a hostgroup
INSERT INTO mysql_servers(hostgroup_id, hostname, port)
VALUES (20, 'new-cluster-endpoint.rds.amazonaws.com', 3306);
LOAD MYSQL SERVERS TO RUNTIME;
SAVE MYSQL SERVERS TO DISK;
-- Step 2: Configure the mirroring rule
-- Option A: Replicate traffic for a specific user
INSERT INTO mysql_query_rules (rule_id, active, username, mirror_hostgroup, apply)
VALUES (1, 1, "your-read-only-user", 20, 1);
LOAD MYSQL QUERY RULES TO RUNTIME;
SAVE MYSQL QUERY RULES TO DISK;
-- Option B: Replicate all traffic for any user
INSERT INTO mysql_query_rules (rule_id, active, mirror_hostgroup, apply)
VALUES (2, 1, 20, 1);
LOAD MYSQL QUERY RULES TO RUNTIME;
SAVE MYSQL QUERY RULES TO DISK;
What We Gained#
🎯 Live Workload Validation: We didn’t need a synthetic stress testing tool. By mirroring production traffic, we were stress-testing the new 8.0 cluster with the most realistic workload possible.
🔥 Cache Pre-warming: As the 8.0 cluster processed live queries, its internal caches (like the query cache and buffer pool) were pre-warmed with the most frequently accessed data. This was critical for ensuring minimal latency spikes during the final cutover.
📝 Note on Write Traffic: While our rule above mirrors INSERT, UPDATE, and DELETE queries, ProxySQL’s mirroring is not a replication mechanism for write traffic. It cannot guarantee the order in which write statements are applied to the mirrored cluster. For example, if two separate update statements arrive almost simultaneously, ProxySQL cannot ensure they are applied in the same sequence on the mirrored database as they were on the primary. Therefore, we rely on MySQL’s built-in asynchronous replication to ensure data consistency for all writes. Query mirroring is strictly a tool for performance validation and read-only workload testing. More details can be found in the ProxySQL FAQ.
3️⃣ Validation Phase: Trust, but Verify#
With live traffic hitting the new cluster, we moved into the validation phase. This wasn’t just a quick check; it was an exhaustive process.
✅ Replication Integrity: We continuously monitored replication lag between 5.7 and 8.0, ensuring the new cluster was never more than a few seconds behind.
📊 Performance Monitoring: We analyzed slow query logs using
pt-query-digestfrom the Percona Toolkit. This tool “fingerprints” similar queries (e.g.,SELECT * FROM users WHERE id = ?) to group them into classes and provides key metrics like average execution time, rows examined, and lock time. This allowed us to identify resource-intensive queries and directly compare performance between old and new clusters, spotting any regressions. Learn more in the pt-query-digest documentation.🔍 Query Plan Analysis: The MySQL optimizer can choose different execution plans between versions, which can lead to unexpected performance changes. We used
EXPLAINto compare estimated execution plans for critical queries between clusters. Profiling was also used to confirm optimizer decisions truly improved performance and to spot regressions. Queries were tuned as needed (e.g., adding indexes or using optimizer hints).🧪 Application-Level Checks: Application teams validated mirrored traffic results, looking for subtle differences in returned data, ensuring migration wouldn’t break business logic.
🌀 CDC Continuity: We confirmed Debezium + Kafka pipelines streamed binlogs from the new 8.0 cluster without interruption.
4️⃣ Cutover: Minutes, Not Hours#
During a pre-scheduled maintenance window, the cutover was orchestrated via Ansible automation. The process was fast and transparent to our engineering team.
📴 MySQL
read_onlyvariable inverted: 5.7 → ON, 8.0 → OFF. Determines whether the server accepts writes.🔁 Replication reversed: 5.7 cluster became a replica of the new 8.0 cluster.
🌐 ProxySQL hostgroups updated: All traffic routed to the new 8.0 cluster.
The entire cutover took only a few minutes, with downtime communicated in advance.
5️⃣ Rollback: The Mandatory Safety Net#
Our migration was designed assuming possible failure.
🛡️ Immediate fallback: The 5.7 cluster, now a replica, was ready to be promoted back to primary.
⏱️ Fast recovery: Any post-cutover issue could be mitigated in minutes, minimizing impact. This safety net was tested and documented before the upgrade.
🚀 ShipHero’s Key Takeaways#
🔑 Control is Safety: For mission-critical systems, don’t rely on opaque managed solutions. Self-managed processes provide predictability and security.
🎯 Query Mirroring is a Game-Changer: Validates performance and pre-warms caches with real workloads, removing the need for complex synthetic load testing.
⏪ Always Design for Rollback: A successful migration isn’t just about moving forward—it’s about being able to go back safely. An immediate rollback plan is non-negotiable.
🤝 Collaboration is Crucial: Migration success depended on close collaboration with development teams, who helped remove, tune, and refactor queries that changed behavior between versions.
🤖 Automate Everything: From infrastructure provisioning with Terraform to traffic management with ProxySQL and orchestration with Ansible, automation reduces human error and downtime.
We hope this deep dive into our process helps you navigate your own complex database upgrades. Wishing safe upgrades for all! 🎉